
 Enterprises
Enterprises Partnership
Partnership Industries
Industries FAQs
FAQs Company
Company
Creating a lengthy PDF without an outline is like wandering in a new city without a map: you can easily lose your way. Fortunately, with tools like PDF Reader Pro, adding structured outlines to your PDFs is simpler than ever.
- How to Create Outlines in PDF for Windows
- How to Create Outlines in PDF for Mac
- How to Create Outlines in PDF: Best Practices
- How to Create Outlines in PDF: FAQ
How to Create Outlines in PDF for Windows
Step 1: Expand "Outline".
Click on the bullet point icon within the left-side panel on top; it should say "Outline".
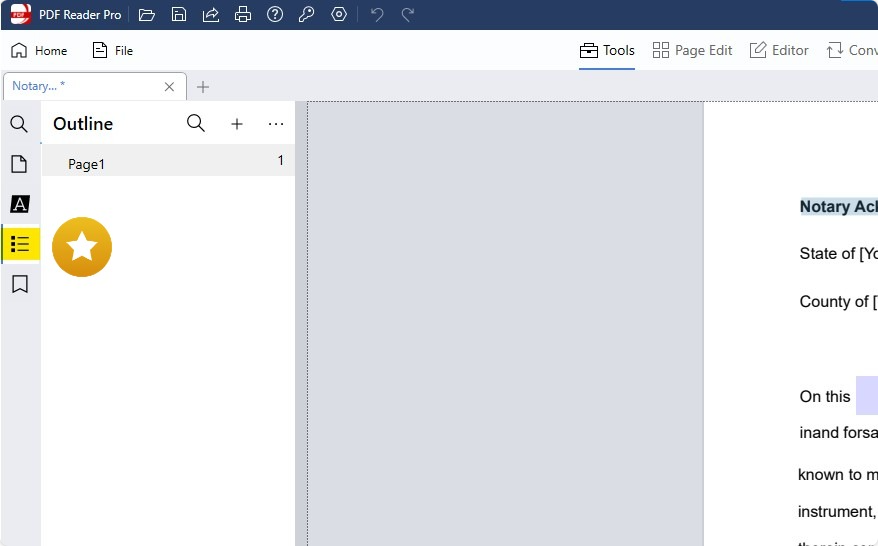
Step 2: Highlight the text you want to turn into an outline.
Right-click the highlighted text and click "Add Outline Item".
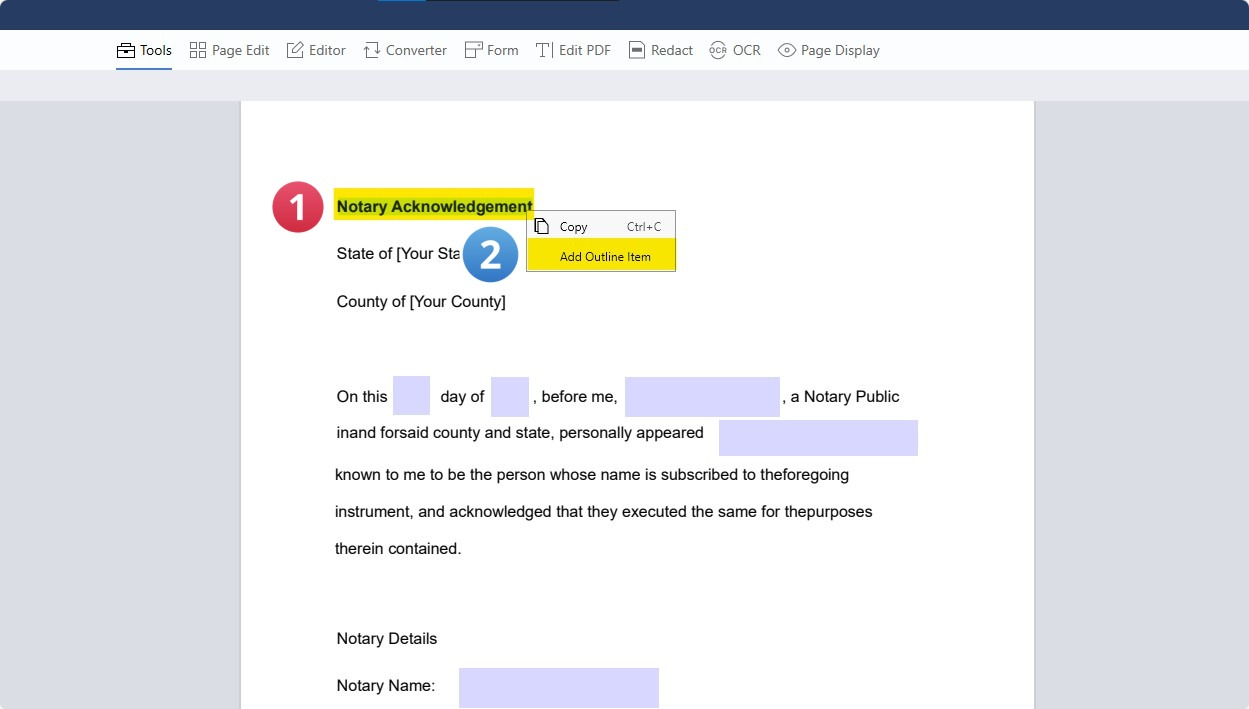
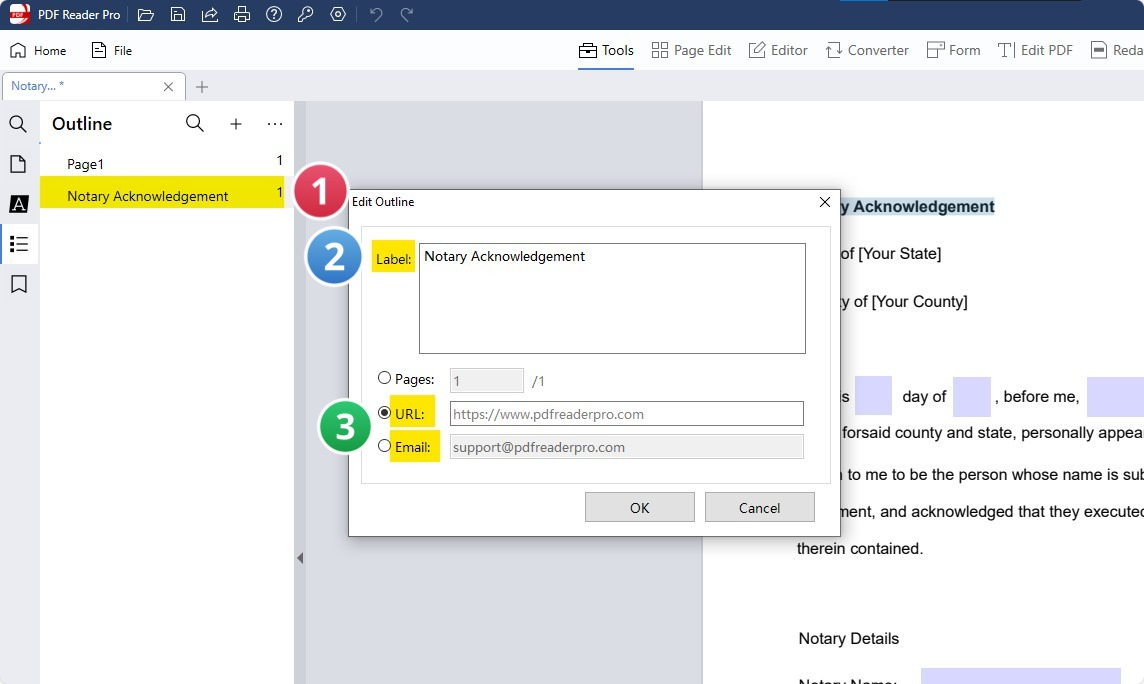
Step 3: Edit your Outline
Add emails or URLs to your outline. Finish by clicking "OK".
Now, you can create outlines for all your lengthy PDFs!
How to Create Outlines in PDF for Mac
Step 1: Expand "Outline"
Click on the bullet point icon within the left-side panel on top; it should say "Outline".

Step 2: Highlight the text you want to turn into an outline.
Control-click (or right-click) the highlighted text and select "Add Outline Item."

Step 3: Edit your Outline
Add emails or URLs to your outline if needed. Conclude by clicking "OK."
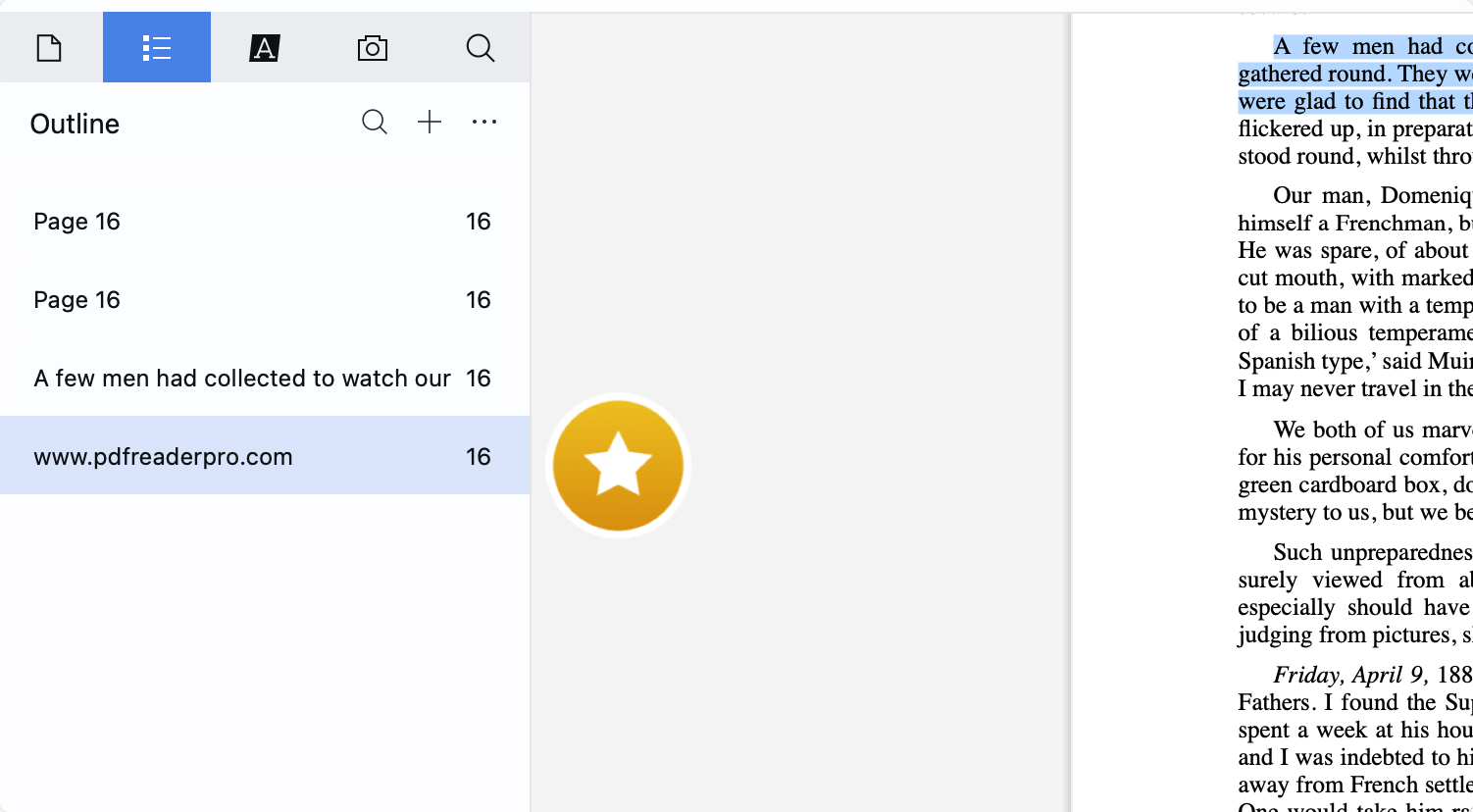
Creating outlines is that easy with PDF Reader Pro!
Creating outlines in PDF Reader Pro has been immensely helpful for organizing my thoughts and structuring my documents efficiently, a vital part of my process as a content writer.

Equally beneficial is the page layout function, which allows me to visually arrange, preview, and delete pages, ensuring that the flow and presentation of my work are exactly as intended.
 Free Download
Free Download  Free Download
Free Download
Merging PDFs is also another tool I use a lot! This combination of features significantly helps my writing and editing process, making PDF Reader Pro invaluable in my content creation toolkit.
How to Create Outlines in PDF: Best Practices
Creating an effective outline in PDF Reader Pro can significantly enhance your document's navigability and organization. Here are some best practices to follow:
- Understand Your Document's Structure: Identify main sections and key points for a coherent outline structure.
- Use Clear, Concise Titles: Choose straightforward titles for easy navigation.
- Maintain Consistent Formatting: Apply uniform formatting to headings and subheadings for clarity.
- Link to Specific Pages or Sections: Make your outline interactive with direct links.
- Regularly Update the Outline: Keep the outline current with document changes.
- Test Your Outline: Ensure all links direct correctly to the intended content.
- Seek Feedback: Get input from others to refine the outline.
- Use Bookmarks for Additional Navigation: Complement your outline with detailed bookmarks.
You can also look at our perspectives on The Future of Green Technology.
How to Create Outlines in PDF: FAQ
What tools do I need to create an outline in a PDF?
You need a PDF editing tool with outline creation capabilities, such as PDF Reader Pro, which allows for the addition of titles, links, and hierarchical organization.
Can outlines in PDFs include links to external websites?
Yes, some PDF editors, including PDF Reader Pro, allow you to add external links in your outlines, directing readers to websites for additional information.
How detailed should my PDF outline be?
The detail in your outline should match the document's complexity. For extensive documents, a detailed outline with nested subsections is helpful. For shorter documents, a simpler outline may suffice.
Is it possible to automatically generate an outline in PDFs?
Some PDF editing tools can automatically generate outlines based on the document's existing headings and formatting, but manual adjustments are often necessary for accuracy.
Can I edit an existing outline in a PDF?
Yes, with PDF Reader Pro, you can modify an existing outline by adding, removing, or adjusting entries and links as needed.











 Support Chat
Support Chat